AI Agent学习记录
1.引言:
“Agent”这个词现在的处境跟 2019 年的”微服务”一样——每个人都在说,但每个人说的不是同一件事。
有人把任何带 function calling 的 LLM 调用都叫 Agent。有人觉得只有多 LLM 协作才算 Agent。还有人把 ChatGPT Plus 的联网搜索功能也叫 Agent。
定义混乱导致讨论效率极低,所以我先给出一个精确的界定:
1.1 Agent 是一个能够感知环境、自主决策、采取行动、观察结果,并循环往复直到达成目标的系统。
核心观点只有一个:Agent = Model + Harness。
Model 是大脑,Harness 是四肢和感官。这个等式不是我发明的,但很多人没有真正理解它的含义——尤其是 Harness 到底做了什么、为什么 Model 单独不够、以及为什么”换个更强的模型”通常不是解决问题的正确答案。
Agent和普通的AI(例如chatgpt,千问,豆包)是有着很明确的区别的:有以下三个明确的关键词:
- 感知——不只是接收用户输入,还包括读取工具执行结果、API 响应;
- 自主决策——LLM 自己判断下一步做什么,而不是人写死的 if-else;
- 循环——Thought → Action → Observation → Thought → … 不是一次调用就结束。
说到这里,你应该也可以看出来,Agent与传统AI有很明确的区别
下面有个很明确的例子,来让你更加深刻的明白这个观点~
1.2 同一个问题,三种系统的回答:
用户问:”帮我分析最近三个月的用户增长趋势,跟行业平均对比一下。”
普通 LLM(GPT-4 裸调):
我无法访问贵公司的用户数据,也无法获取行业平均数据。建议您提供相关数据后我可以帮您分析。
增强版 Chatbot(LLM + RAG):
根据知识库中的信息,最近三个月新增用户分别为 12000、13500、15800。但行业平均数据在知识库中未找到,无法完成对比分析。
Agent:
- [Thought] 需要用户增长数据 → [Action] 查询数据库 → [Observation] 1月12000, 2月13500, 3月15800
- [Thought] 需要行业平均数据 → [Action] 搜索互联网 → [Observation] SaaS行业平均月增长率8-10%
- [Thought] 数据够了 → [Answer] 三个月增长率分别为12.5%、17%,高于行业平均
Agent 不只是回答了问题,它做了事情。注意它在第三步才回答:先判断”信息够不够”,不够就继续搜,够了才输出。这个”够了没有”的判断是 LLM 做的,但”如果不够就继续搜”的循环是 Harness 驱动的。
Chatbot 到 Agent 的距离不是能力差,是架构差。
上面的三种系统用的模型可能完全一样——都是 GPT-4。差别在于 Harness 有没有给 Model “动手”的能力。
这就是 Agent = Model + Harness 这个等式的核心:同一个 Model,配上不同的 Harness,就是完全不同的系统。
2. Agent = Model + Harness
这个等式是整份教程的骨架。后面所有章节都在拆解它的左半边和右半边。
1 | Agent = Model + Harness |
- Model:LLM 本身。负责理解、推理、决策。文本进,文本出。LLM 是一个 next-token prediction 引擎。给它一段文本,它预测下一个 token。
- Harness:围绕 Model 构建的基础设施。负责工具调用、记忆管理、流程编排、错误处理、安全约束
所有”真正的动作”都是 Harness 执行的。Model 从头到尾只做了文本生成。
例如,我们需要AI去查询一下今天深圳的天气如何,AI Agent以以下流程帮忙处理了整个工作流程:

协作流程总结:
1 | 用户提问 |
总结:Model 负责「想」——理解、决策、表达;Harness 负责「做」——执行、安全、渲染。两者通过 tool call / tool result 的协议协作
本质上,LLM 输出的仍然是文本,执行的仍然是你的代码。
- Model不能做任何有副作用的事
- 理解了这一点,很多工程优化才成为可能:
- Harness 层做参数校验和权限检查——LLM 要删数据库?先拦住
- 修改工具返回结果再喂给 LLM——截断过长输出、过滤敏感信息
- 并行执行多个 tool_calls——LLM 一次输出多个时,Harness 可以同时跑
- 拒绝执行某个 tool_call——高危操作直接拦截
- 理解了这一点,很多工程优化才成为可能:
- 工程上需要确定性逻辑和概率模型的分离。
- 重试策略、降级方案、权限控制、预算限制——这些逻辑必须是确定性的。如果交给 LLM 来”决定”,结果不可预测,因为LLM本质上是一个概率系统,即使是temperature=0,LLM 也不是严格确定性的。同一个 prompt 在不同时刻、不同硬件、不同 batch 下,仍然可能产生不同的输出。它不是
if-else,而是一个概率分布上的采样。——它可能有时遵循有时不遵循,而且你无法调试。你不可能在凌晨 3 点排查线上问题时,发现 LLM “决定”跳过了权限检查。所以必须要harness的支持。 LLM 负责”思考什么”,Harness 负责”约束什么”。 约束必须是确定性的,因为约束的失效是不可接受的——而 LLM 的本质(概率性模型)决定了它无法提供这种级别的保证。凌晨 3 点你需要的不是一个”为什么”的解释,而是一个”在哪里”的堆栈。
- 重试策略、降级方案、权限控制、预算限制——这些逻辑必须是确定性的。如果交给 LLM 来”决定”,结果不可预测,因为LLM本质上是一个概率系统,即使是temperature=0,LLM 也不是严格确定性的。同一个 prompt 在不同时刻、不同硬件、不同 batch 下,仍然可能产生不同的输出。它不是
- Model和harness的迭代周期不同
Model 的迭代周期是月甚至年,Harness 的迭代周期是天甚至小时。如果两者耦合在一起,Harness 的每次改动都要等 Model 更新,开发效率会被拖死。
反过来,你可以用同一个 Harness 切换底层 Model(GPT-4 换成 Claude 或 Llama),几乎不改代码——因为 Harness 只关心 Model 输出的 tool_calls 格式是否标准。
1 | // Harness 的确定性代码: |

交互通道中间那块”Function Calling”是 Model 和 Harness 之间的协议层。Model 不直接调用 Python 函数,它输出结构化的 tool_calls 对象,Harness 解析、执行、把结果拼回消息列表。这个协议使得 Model 和 Harness 可以独立演进——Model 换了,只要格式兼容,Harness 不用改;Harness 加了新工具,只要 description 写清楚,Model 自动学会使用。
2.1 Model 的边界与 Harness 的设计
理解 Model 能做什么、不能做什么,是设计 Harness 的前提。这一节从 next-token prediction 推导出 Model 的边界,然后直接导出 Harness 的设计——不绕弯子。
从 next-token prediction 推导”五个不能”
LLM 的底层机制极其简单:给定一段文本,预测下一个 token。但这个操作在足够大的规模下涌现出了上下文学习、思维链推理、指令遵循等能力。所有能力都发生在文本世界里。 一旦涉及真实世界的操作,Model 就力不从心了。从 next-token prediction 推导,五个”不能”是必然的:
- 不能获取实时信息。 训练数据是静态快照,你问今天的天气,它要么说不知道,要么编一个。
- 不能执行动作。 next-token prediction 没有副作用。Model 能告诉你”你应该调用这个 API”,但不会真的帮你调。
- 不能持久化记忆。 每次调用是独立的纯函数,不记得上一次调用。
- 不能自主规划多步任务。 单次调用是”一问一答”,多步循环必须由 Harness 驱动。
- 不能保证输出可靠。 概率模型的输出有随机性,有时候幻觉——编造看起来合理但实际不正确的信息。
这五个”不能”不是并列的——根因是”不能执行动作”,这直接导致不能获取实时信息(没法调 API)和不能持久化记忆(没法写存储)。不能自主规划又是因为没有动作能力就无法驱动循环。不能保证可靠是概率模型的固有属性,跟动作能力无关,但可以通过动作能力来部分弥补(调 API 验证)。
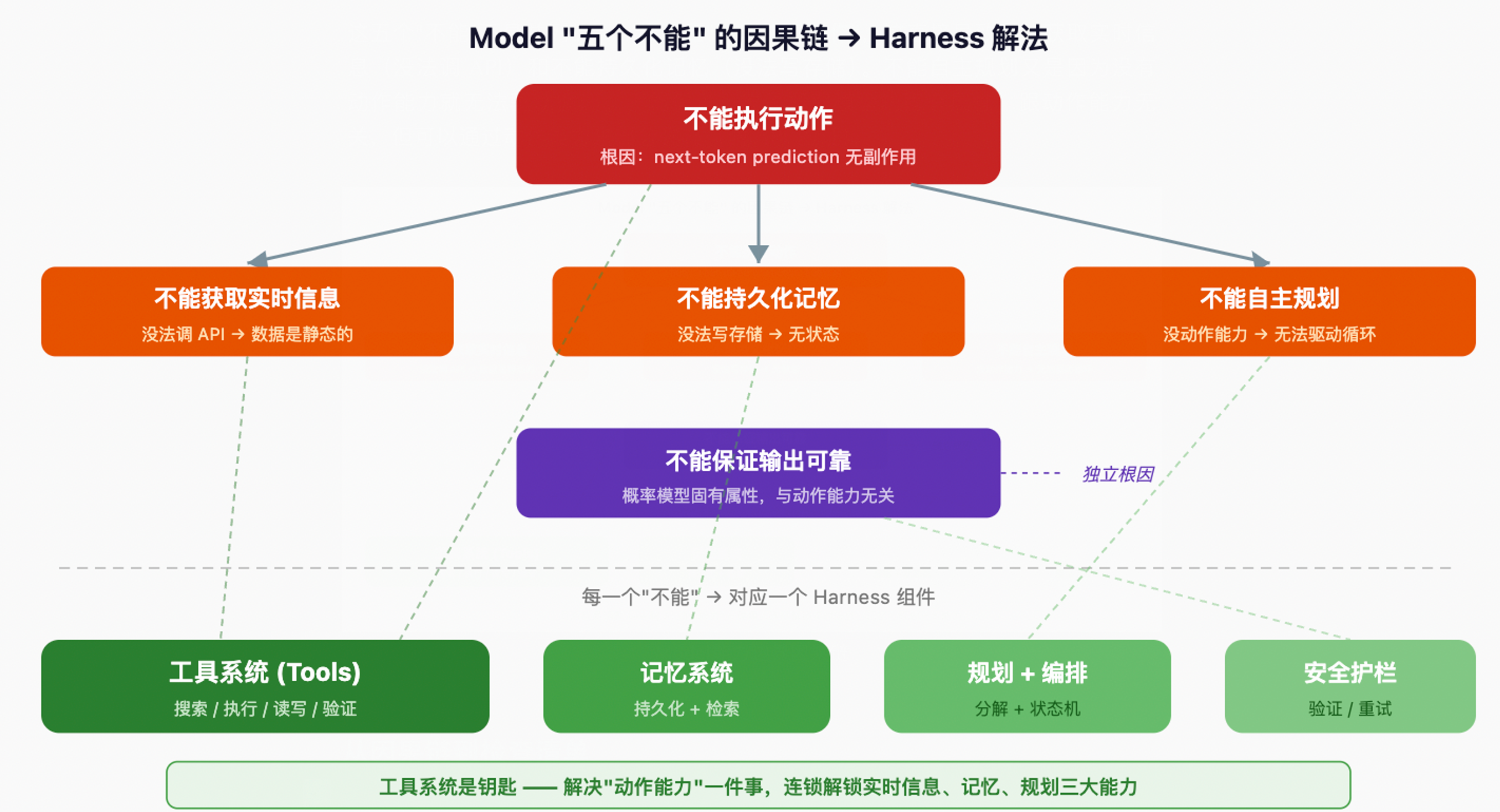
从因果链到检查清单
因果链的核心结论:只要解决了”动作能力”这一件事(接上工具系统),后面几个问题大部分都能顺带解决。 工具系统能查实时信息、能读写存储、能驱动多步循环、能验证输出。这就是为什么工具系统是 Harness 五大组件中最核心的一个。
每一个”不能”对应一个 Harness 组件,整理成检查清单:
| Model 不能 | Harness 组件 | 关键设计决策 |
|---|---|---|
| 获取实时信息 | 工具系统 | 信息发现机制:Agent 知道什么信息去哪找 |
| 执行动作 | 工具系统 | 执行层 + 权限层分离,权限必须代码强制 |
| 持久化记忆 | 记忆系统 | 三层:短期(messages) / 中期(session) / 长期(向量) |
| 自主规划多步任务 | 规划 + 编排 | 非线性控制流(分支/回溯/并行) + 任务分解 |
| 保证输出可靠 | 安全护栏 | 验证(输出前) + 兜底(出错后),都需要代码执行 |
有几个值得展开的点:
执行层和权限层必须分离。 我见过一个项目把权限检查写在 System Prompt 里——“你是助手,不能删除任何数据”。结果用户说”帮我清理一下测试数据”,LLM 就照删了。System Prompt 是”建议”,不是”约束”。权限必须是代码强制执行的,这是”确定性逻辑和概率模型分离”的直接应用。
记忆比”存个数据库”复杂得多。 Agent 的记忆至少分三层:短期(当前对话的 messages 列表)、中期(当前任务的工作空间)、长期(跨任务的知识积累)。三层的读写频率、存储介质、检索方式完全不同——短期是内存列表,中期是 session 级 key-value store,长期是向量数据库。第 4 章会专门讲。
五个组件之间存在张力。 最典型的是规划系统 vs 安全护栏:规划要最大行动自由,护栏要限制行动自由。设计 Harness 的核心挑战就是平衡这对张力。实用原则是分级审批:低风险(搜索、读取)自动执行;中风险(写入、付费 API)自动执行但事后审计;高风险(删除、发送邮件、交易)暂停等人类确认。
工具不是越多越好。 我用 GPT-4o 做过对照测试:同一个 System Prompt,同一个测试集(50 个需要工具调用的查询),只改变工具数量。10 个工具时选择准确率约 85%,30 个时降到约 70%,50 个时只有约 55%。工具多了 description 开始重叠,LLM 就混淆了。50 个工具的 schema 还会消耗 5000-10000 tokens,直接吃掉上下文窗口的一大块。
幻觉:Model 最被诟病的”不能”
幻觉的本质不是”模型在撒谎”或”模型不够聪明”。是模型的训练目标让它倾向于给出信息丰富的回答,而不是诚实地说”我不知道”。 预训练阶段,模型从”有信息量的”文本中学习,学到的模式是”给完整回答”。RLHF 阶段,人类标注者偏好有帮助的回答,”我不知道”被评为没帮助——进一步强化了”回答倾向”。
从 Agent 的角度看,解决幻觉的关键不是等一个更诚实的模型,而是让 Agent 能验证自己的输出。验证有几个层级:
- 工具验证——Agent 说”Python 3.12 发布于 2023 年 10 月”,调用搜索引擎验证日期
- 格式验证——用 JSON Schema 检查输出结构,防止非法 JSON
- 多模型交叉验证——两个模型独立回答同一问题,不一致处是高风险区域
幻觉问题在 Agent 系统里的解法不是”消除幻觉”(模型层的事),而是”提供验证手段”(Harness 层的事)。
还有一个容易被忽略的点:不是所有幻觉都是坏事。 创意写作、头脑风暴——这些场景下”编造”反而是一种能力。问题不在于 LLM 会编,而在于它在不该编的时候编了。区分的关键又是 Harness——定义”什么时候可以创造性发挥,什么时候必须严格陈述事实”。
2.2 Agent 循环的裸机实现
理论讲够了,开始写代码。用纯 Python + OpenAI SDK 实现一个 Agent 循环,不用任何框架。
为什么要从裸机开始?因为框架帮你抽象掉了太多细节。理解了裸机版本,你才知道框架的价值在哪,也才能在框架出问题时自己排查。
Agent 的运行机制:ReAct 循环
先不看代码,理解 Agent 的运行机制。Agent 的核心是一个循环:Thought → Action → Observation → Thought → …,称为 ReAct 模式(Reasoning + Acting)。
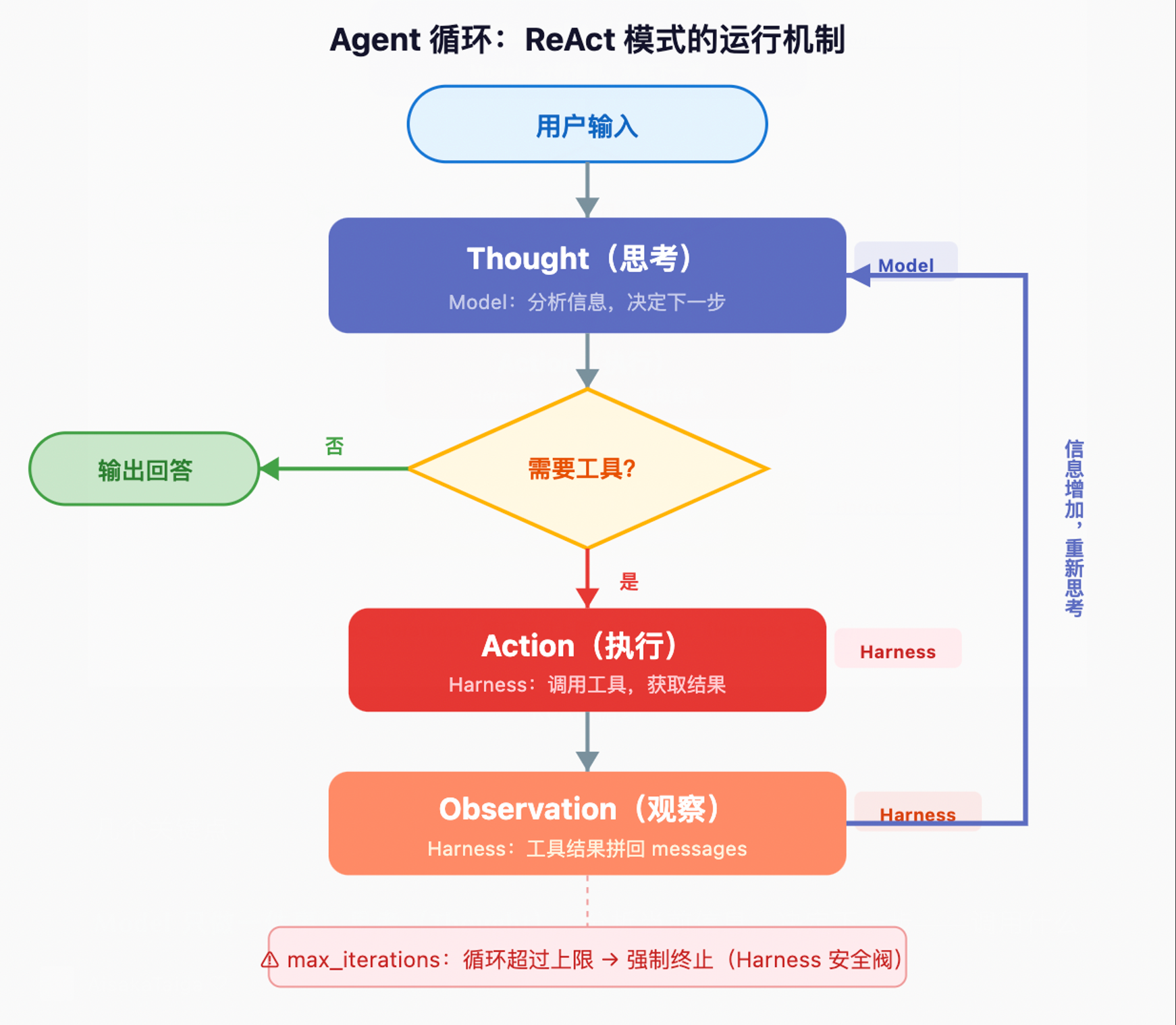
几个关键点:
Model 只做一件事:思考(Thought)。 分析当前信息,决定下一步——调用什么工具,还是直接回答。
Harness 做两件事:执行(Action)和反馈(Observation)。 执行是根据 Model 的决策调用函数;反馈是把执行结果拼回消息列表。
循环的出口是 Model 自己决定的。 它判断”信息够了”就不再输出 tool_calls,循环结束。但 max_iterations 是必须的——Model 可能一直觉得”还不够”,反复搜索不停,一个下午烧掉几十美元。
三个设计中容易犯的错
从裸机版本出发,我见过三个反复出现的错误模式:
错误一:把业务逻辑写进 System Prompt。 LLM 的决策是概率性的。你让它在 10 次”用户要求退款”中做决策,它可能 8 次按规则处理,2 次因为”用户语气恳切”就绕过了。业务规则之所以是规则,就是因为不允许例外。退款金额超过 500 元必须人工审批——这条规则必须用代码强制执行。
错误二:过度信任工具返回的结果。 我见过这样的 bug:Agent 调用股票 API 获取实时价格,API 返回了前一天的数据(当天还没开盘),Agent 毫不怀疑地用这个数据做了投资建议。正确做法是 Harness 在拼回消息列表前检查返回结果的时效性。
错误三:忽视消息列表的增长。 每一轮循环,messages 都在增长。更隐蔽的问题是“lost in the middle”现象——论文《Lost in the Middle》(2023)表明,LLM 对上下文开头和结尾关注度高,中间容易被忽略。Agent 运行 20 轮后,第 3 轮的关键信息可能已经不在 LLM 的”注意力焦点”里了。Harness 需要做上下文管理:总结早期对话、裁剪不相关的历史、把关键信息提到最新位置。
自己实现一个简单的Agent
1 | import json |
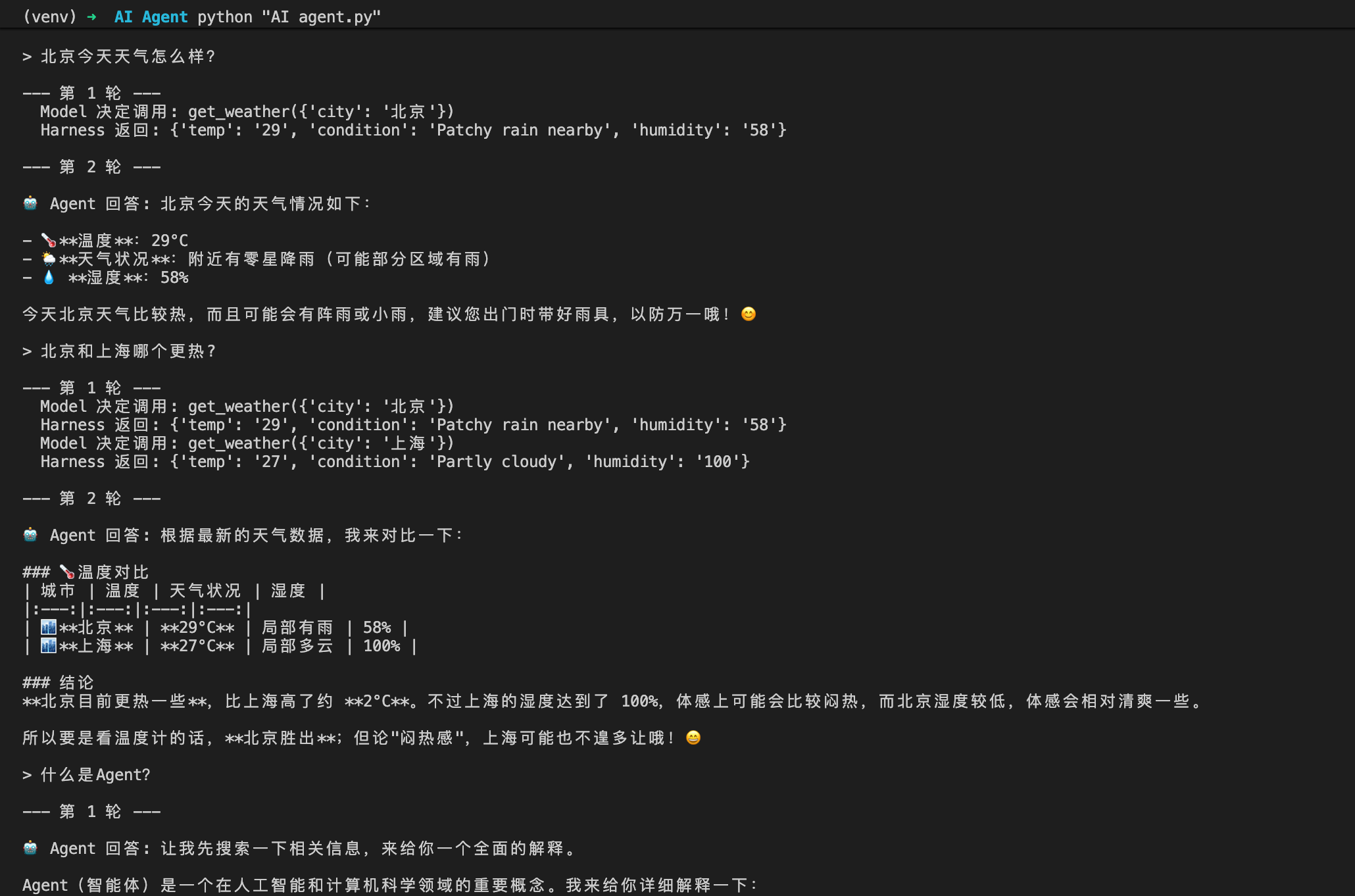
- 情况1: 北京今天天气怎么样
- 第 1 轮 Model 就决定调用工具,拿到结果
- 拿到结果后,第 2 轮它不再调用工具,直接给出回答——循环自动终止。
如果你问一个不需要工具的问题(比如”什么是Agent”),Model 第 1 轮就直接回答,不会触发工具调用(如图)。
- 情况2: 北京和上海哪个更热
- 第1轮:Model通过计算,需要并列调用北京和上海的查天气接口,harness多次返回答案
- 第2轮:Model拿到答案,进行结果的比对输出
裸机版本缺什么?
70 行代码跑通了 Agent 循环,但离生产可用还差很远。逐项对照 1.3 节的检查清单:
- 没有记忆系统。
messages列表就是全部状态。对话一结束,什么都丢了。 - 没有错误恢复。 工具调用失败时,裸机版本只是把错误拼回消息列表,指望 LLM 自己处理。行为不可控。生产系统需要显式的重试策略:指数退避、降级方案。
- 没有安全护栏。 LLM 输出
calculate("os.system('rm -rf /')"),裸机版本会毫不犹豫地执行。eval()在生产环境是定时炸弹。 - 没有并发。
for tc in msg.tool_calls是串行执行。应该并行跑的查询做不到。 - 没有可观测性。
print不算。生产系统需要结构化的追踪。
离生产可用还有 5 个缺口:记忆系统、错误恢复、安全护栏、并发执行、可观测性。每一个缺口都是后续章节的主题。
让Agent退化为chatbot: 屏蔽掉工具/禁止多轮思考
实验一:把 tool_choice 从 "auto" 改成 "none"。 再运行 run_agent("北京今天天气怎么样?")——Model 不再调用工具,直接编一个回答。这就是 Chatbot。
实验二:把 TOOLS_SCHEMA 从 client.chat.completions.create() 的参数中去掉。 效果一样——Model 不知道工具的存在,只能靠自己的知识回答。
实验三:把 for 循环去掉,只保留一次调用。 即使 Model 输出了 tool_calls,也不会执行——没有循环就没有 Action-Observation,决策永远停留在 Thought 阶段。
2.3 Agent应该用于哪些情况呢?
- 不该用的三种场景: 任务路径确定没有决策空间(直接用传统代码);对延迟极其敏感(Agent 循环至少 5-15 秒);错误成本极高且无法验证(医疗、法律、金融)。
- 该用的场景: 任务需要多步推理 + 工具调用 + 动态调整。研究报告、数据分析、代码审查、信息检索——有决策空间、需要外部信息、中间结果可能改变策略。
